去厨神主持的餐厅吃饭,上菜慢,一定要等。因为厨神只有一个。但是在竞争激烈的市场里,应用人工智能 AI技术则不能等,否则可能被颠覆被市场淘汰。
人工智能(AI)的研究已经持续了60多年。最近AI所呈现出的爆发趋势,不单单是因为算法的改进、大数据的积累,更重要的是计算能力的大幅提升和变革。企业和互联网巨头都有自己的算法和数据,但在计算力的获取上一直有比较高的门槛。今天我们重点谈AI 时代的计算能力。
随着近年来硅芯片逼近物理的极限和经济成本高升,摩尔定律已趋近失效。使用通用处理器这个传统的方法已无法满足人工智能的各种应用对爆发的和高计算能力的需求。因此,具有GPU、ASIC、 FPGA 或其它加速器(Accelerator)等高并行、高密集的计算能力的异构计算持续火热,而异构计算也将成为支撑先进和以后更复杂AI 应用的必然的选择。
异构计算(Heterogeneous Computing)是指使用不同类型指令集和体系架构的计算单元组成的计算系统。异构计算是性能、成本和功耗均衡的技术,同时也是让最适合的专用硬件去做最适合的事如密集计算或外设管理等,从而达到性能和成本的最优化。
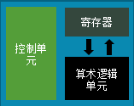
我们熟知的CPU (中央处理器,Central Processing Unit)作为通用处理器,是更偏重支持控制流数据。CPU每个物理核中大部分的硬件资源被做成了控制电路和缓存,用来提高指令兼容性和效率,只有小部分是真正用来做计算的逻辑运算单元(ALU)。在没有AI或其它高计算力要求时,CPU可以应付得绰绰有余,在AI或高计算力要求时,从计算任务执行效率来看,尽管CPU能兼容大量指令,但是实际的计算效率并不高。相反,CPU 在异构系统当中,可以扮演和发挥非常重要的指挥统筹,控制核心的功能。
做个比喻吧,CPU 可以看成一个“大厨”,各大菜系烹饪了如指掌,可以做出各式各样不同口味的菜品满足各类人群的需求。但“大厨”由于要负责厨房里的方方面面,对一些大量而特定的复杂处理就显得力不从心,比如一千位客人要吃各种土豆丝,比如酸辣土豆丝、青椒土豆丝、土豆丝炒肉,需要助手在短时间内切出大量长短薄厚相同的土豆丝,于是“大厨”需要找个帮手(GPU,FPGA或ASIC)来协助,这个帮手可以同时处理很多土豆(并行处理),而且速度很快(低延时),最后在与“大厨”的合理分工协作下,能满足客户对菜品的需求。
也许有人会说,可以再雇个“大厨”,这样组成一个同构厨房(Homogenous Computing,同构计算系统)不好吗?当然可以,之前的多CPU就是这么做的,但是在当前基于人工智能应用的计算密集型负载上,这种同构厨房有明显的缺点。首先,“大厨”身价很高,而且在某些具体的应用上也不擅长,比如快速切土豆丝;其次,“大厨”很健忘,需要总是翻看菜谱(访问内存)。由此可见,一个高效的厨房需要“大厨”和一群擅长各种任务的“帮厨”高效沟通和协同合作。
“大厨”CPU的重要帮手们我们知道在异构计算大厨房里常见的计算单元类别除了“大厨”CPU之外,还有众多帮手如GPU、ASIC、FPGA、DSP等。那么,这么多的计算单元各自有什么特长呢?
GPU:适于大范围、多任务的简单运算
GPU 是图形处理器(Graphics Processing Unit)的缩写。顾名思义就是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上进行图像运算工作的微处理器。近年来,GPU在深度学习方面应用广泛,主要是因为针对于神经网络这种大范围多任务的简单运算来说,正好符合GPU这种多核架构,就好像几万个客人同时点了酸辣土豆丝,需要大量的“帮厨”快速切好几万盘土豆丝。
不过, GPU虽然土豆丝切的又快又好,但如果你要跟他说,几个土豆切丝,几个土豆切块,再配上几个青椒,然后去冰箱拿些猪肉,做一盘复杂的大菜,那就力所不及了。这是因为复杂的控制流程会产生大量的分支,而GPU中一个控制单元要负责好几个计算单元。所以,如果要最大程度地使用GPU,势必要求指令简单特别是控制分支越少越好。
另外,GPU也有CPU“大厨”的毛病:健忘(需要从内存读取指令)。这带来了一系列问题,如存储墙,功耗大,基于指令系统,要译码。
ASIC:全自动、定制化
ASIC的全称是特殊应用专用集成电路(Application Specific Integrated Circuit)。它是定制的,也意味着不需要去纠结CPU和GPU怎样分配控制资源和计算资源的问题了,想怎么分配就怎么分配。
编程语言越接近底层硬件,运行速度越快。ASIC所有的设计是直接建筑在物理硬件(门电路)上的。所以ASIC不需要复杂的指令系统,每个时钟周期单位都能专注于数据处理或者传输,因此大大提高了效能。而且因为高度定制化,芯片可以在设计中进行针对性的PPA优化(PPA 是性能Performance,功耗Power和面积Area的简称)。
这么说来,ASIC 像一台全自动定制土豆切丝机,你只要把土豆扔进这个切丝机里,土豆丝很快就切出来了,而且形状一致性好,能耗低,还节省空间。
可见这台定制机简直是厨房神器,完胜CPU和GPU。但是定制机也有缺点,如果客人改变口味,想吃土豆烧鸡,需要把土豆切成块。这样一来切丝机就没法用了,并且在市面上还买不到现成的切块机,需要重新定制。
FPGA:灵活可编程
FPGA 做为异构计算大厨房的重要帮手,和GPU、ASIC又有什么区别呢?
FPGA(Field Programmable Gate Array),即现场可编程门阵列,它是在PAL、GAL、CPLD等可编程器件的基础上进一步发展的产物。关键字是“可编程”,这意味着灵活性。这样,FPGA可以利用预建的逻辑块(LUT, Look-Up-Table)和可重新编程来布线资源,当客户需要土豆丝的时候可以定制成是切丝机,在需要土豆块的时候可以变成切块机。而且,正是因为FPGA里拥有这些大量的可编程逻辑,可以使其做到真正的并行执行,不同的处理操作无需竞争相同的资源,每个独立的处理任务都配有专用的电路部分,能在不受其它逻辑块的影响下自主运作。 因此,添加更多处理任务时,其它应用性能也不会受到影响。
当然 FPGA也有缺点,主要问题在开发。异构算法的开发人员大部分是软件人员,缺乏对FPGA结构和数字电路的了解,编程语言也不统一(CPU端是C、C++等;FPGA端是VHDL、Verilog等底层硬件描述语言)。目前解决这个问题的方法是OpenCL和HLS(High Level Synthesis)技术,支持直接把C、C++代码编译成Verilog,目前转化效果仍然有待提高,这些技术的成熟还需要一些时间。
综上所述,一个具有高效的AI计算能力(厨房)的系统是大家必需要的,这个厨房里需要有经验丰富的大厨(CPU)和身怀绝技的各种帮厨 (加速器),在“大厨”的指挥统筹下,加上帮手们各展所长,并进行有效的协同合作,从而满足客户对美味佳肴不断快速变化的需求。
CPU和加速器的协作的好例子是用IBM POWER9 处理器的新一代服务器。POWER9是专为当前及未来的计算密集型人工智能工作负载而设计,是首批嵌入 PCI-Express 4.0 (2倍PCIe 3.0吞吐量),新一代 NVIDIA NVLink2.0(无缝连接GPU 和CPU)及 OpenCAPI 25Gbps 的通道 (是PCIe 3.0的3倍)。这是最实实在在支撑 异构计算(Heterogeneous Computing)的落地实体。
当然除了支撑 异构计算,POWER9 的服务器也优化了AI负载,例如 大幅提升 Chainer、 TensorFlow 及Caffe 等各大人工智能框架的性能,并加速 Kinetica 等数据库。数据科学家能够以更快的速度构建包括科研范畴的深度学习洞察、实时欺诈检测和信用风险分析等范围的应用。 POWER9 也是美国能源部 Summit 及 Sierra 超级计算机的核心,这两台超级计算机建成后已成为世界上性能最强最智能的超级计算机之一。此外,谷歌公司也采用了基于POWER9 处理器的异构计算平台应用于各种复杂的人工智能负载。
除了算法,数据外,异构计算将会为AI应用带来更强大的支持。异构计算,特别是加速器的发展和创新,将会为业界、最终用户和创业公司带来更无限的商机。